AI Vibes
2025-07-14
For about the last year, my main task at work has centred around the use of AI. It's a huge topic that has lovers and haters, but I thought I'd take the time to write a bit about my experiences, feelings, and progress when dealing with the new technology on the block.
What is AI?
The term Artificial Intelligence isn't new. In fact, the gamer demographic has been very aware of it for over thirty years, before it referred to any kind of neural network.
When I was young, we called pretty much any programming that was supposed to mimic a human player AI. If you were playing a tough computer opponent in Command and Conquer or Age of Empires, you might have said that the AI is really good.
Even in the 2000s, we saw a lot of chat bots that were hailed as indistinguishable from a human. It's hard not to laugh about that now, but at the time they were often called AI too, even though it was probably just a bunch of pre-written responses. There's a neat History of Chatbots, although I feel it misses some of the strange personalities like Clippy.

These days, AI pretty much only refers to neural networks. These are complex graph-like structures that rely on relationships between nodes and edges (which form each layer) to take a set of input values and produce a likely output value. We've moved from a series of if-then rules to control our AIs to a mechanism that relies on probability. Let's take a closer look.
Inside an AI Model
I'm not the best person to explain this if you're looking for a detailed walkthrough, and it would take more than a blog post to get that right. Instead, I'd recommend looking at sites like DeepLearning.ai or checking out videos on neural networks and transformer models on YouTube.
The short explanation is that you start with an untrained structure of your model, where layers of nodes, each with the capability to normalize and store incoming values, are connected to all other nodes of the adjacent layer via edges. Think of edges as conveyor belts. They are moving values forward to the next node, but different edges might have different levels of importance to their destination. Some might not even transport their values at all if those values don't meet a certain threshold.
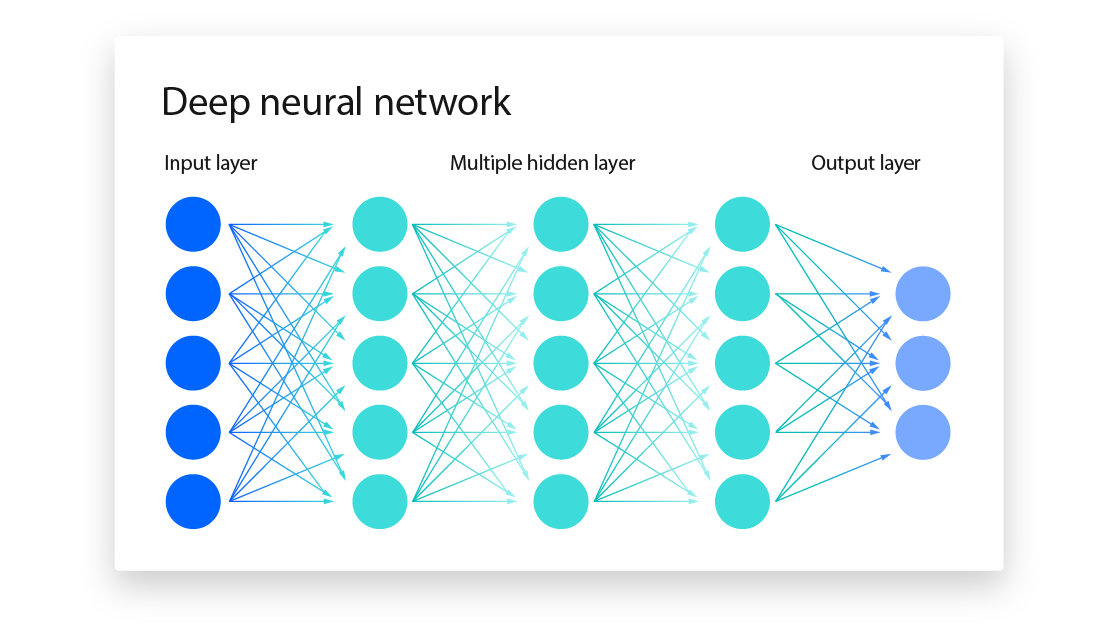
If this already sounds complicated, remember I said I'm not the best person to explain this. At this point the model exists, but it doesn't really know what to do if you were to give it input into the first layer. It would pass things along, but the output would be gibberish, because it has never been trained. This is usually the most compute-intensive part of the process. You need a lot of data for this kind of training, and if you don't have the hardware, it could theoretically take 100s to 1000s of years. That's why we don't train on household computers.
The training process is a lot, but if you have the sample data to train it, then you are essentially providing a set of input values that are taken through the model (you might hear the term feed-forward) just to see what comes out the other side. There are a number of factors that influence whether nodes activate to pass values on to the next layer, but this is all determined by the function used to normalize node values, activation thresholds on those nodes, and weights on the edges used to forward those values to the next layer. By the time the last layer receives its values, it's hopefully something that is useful as a prediction.
And everything is a prediction. The output given is usually seen in terms of probability. Keep in mind the actual output is a large series of floating point numbers, but we'll simplify it here. If the output in my training doesn't match what I expected, we can adjust the configuration of our model (weights, bias, etc.) to hopefully push it towards the answer we expected. This needs to be done thousands if not millions of times until the model is useful. You'll probably hear the term back-propagation to describe this mechanism.
Once there's a trained model, the process of using it is very similar. Input goes in the first layer, it iterates through the layers of the model, then the last layer has the most likely prediction. Let's take an example. If I input the phrase “I washed my”, then I'm expecting a word that should logically end that phrase. “I washed my car” is a pretty acceptable answer, as is “I washed my hands.” The combination of nodes in the final layer of the model that could result in either “car” or “hands” have a high probability of containing the highest value and being selected for output. In a similar vein, “I washed my thankfully” doesn't make sense. The model was probably never trained in a way that would encourage this output, so the values on the nodes that might produce this word are probably near zero.
All of this was a lot of words to say that this isn't magic. It's math with a lot of variables. AI outputs are not deterministic and should not be treated as or relied upon as anything more than a confident guess.
My Vibes
On the spectrum of hype around AI, I find myself somewhere on the lower side. It's undoubtedly a game-changing tool for prediction and pattern detection. In government, there's already a range of uses, from forest fire predictions to document analysis. What I hate to hear from my colleagues are the claims that AI has already made the work of IT obsolete as well. Having worked hand-in-hand with it, I'm confident to say there's no threat there.
Another part of why I think there's a bad view of AI in a lot of communities is that it's used irresponsibly and in cases where it's not needed. What I'm seeing a lot of in the software development world is the view of AI as a must-have item for clients. Because it's popular, they want to be able to say their application uses it, even if it's not best for the users. At the end of the day, this usually just means wrapping another offering like ChatGPT, Gemini, or another service, then building a system around this. This isn't inherently bad, but we need to ask the question: could this have been done without AI?
A specific example I've run into was around creating references between legal documents. In our BC Laws, there are often references to other acts or regulations that will look like this: Section 3 (1)(a)(iv), which means section 3, subsection 1, paragraph a, subparagraph 4. Our goal was simply to link a node in our graph database to the node it was referencing.
A coworker was dead set on a process that required Named Entity Recognition, using Claude 3.5 to mark texts in a way that they hoped would allow them to connect them easily. They even tried fine-tuning their own NER model for this task. They were too caught up in the hype of AI to see that the results were disappointing. They even tried using the Azure GraphRAG offering, but it lacked the context needed to connect things properly. To it, all section 3s were the same, even if they weren't from the same document.
In the end, I just decided to tackle the problem with good-ol' regex. Some people can't stand it, but it got 90% of the references without too much hassle, and it is blindingly fast with zero cost. Compare that to the hours of processing needed for an AI model or the thousands needed for services in Azure, and it was clear that this wasn't a problem we needed AI to solve.
Next Time
I've written a lot in general terms here, but next time I'd like to show off a few things that I've actually been working on in the AI space. It's not all doom and gloom!